![]()
![]()
Interactive package for Short AsyNchronous Time-series Analysis (SANTA), implemented in R and Shiny
Overview
santaR is an R package that implements functions for analysis of short asynchronous time-series analysis.
santaR can deal with challenges not simultaneously addressed by current time-series statistical methods: - missing observations - asynchronous sampling - measurement error - low number of time points (e.g. 4 to 10) - high number of variables - biological variability - nonlinearity
The reference versions of santaR is available on CRAN. Active development and issue tracking take place on the github page, while an overview of the package, vignettes and documentation are available on the supporting website.
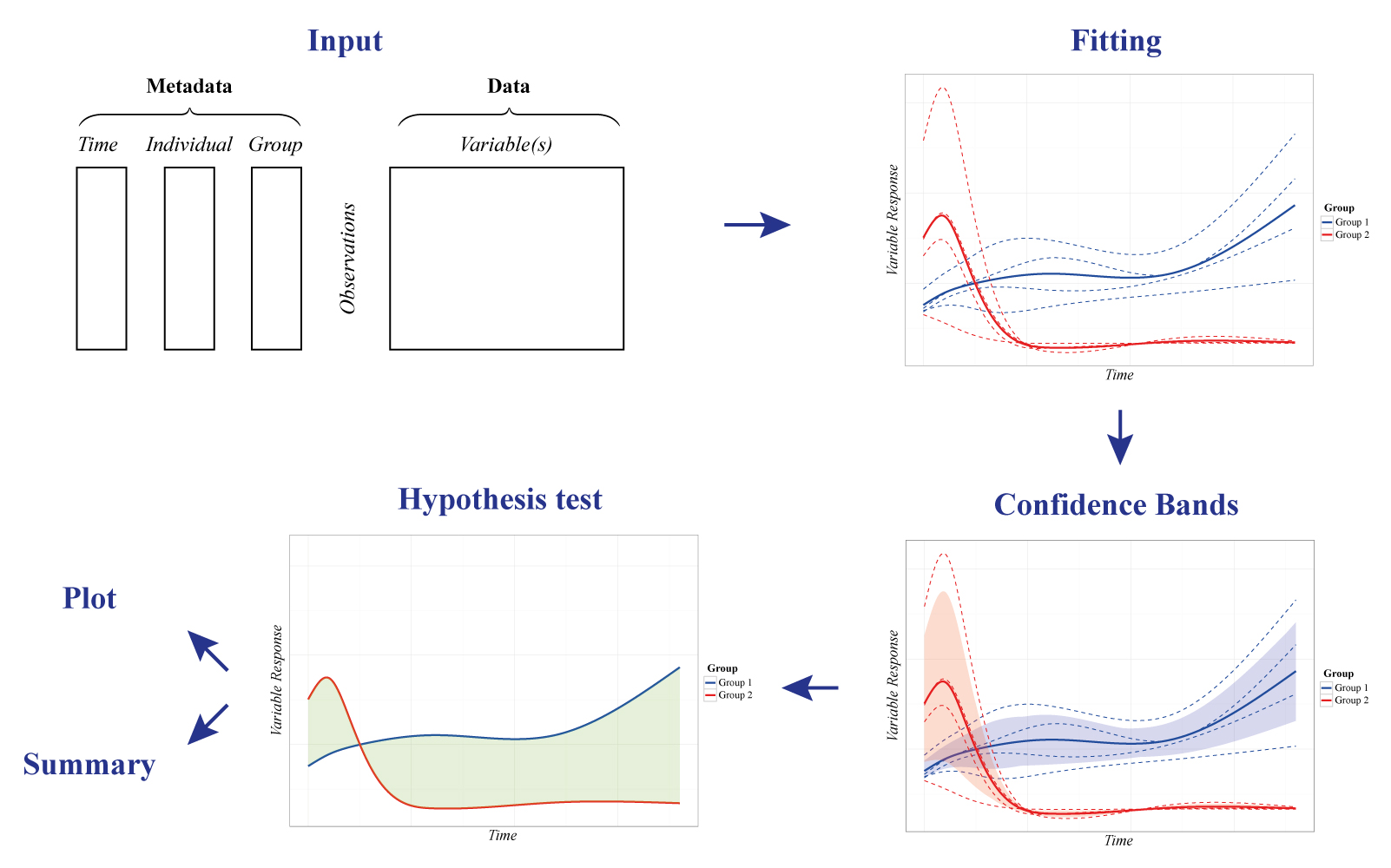
To address the challenges of time-series in Systems Biology, santaR (Short AsyNchronous Time-series Analysis) provides a Functional Data Analysis (FDA) approach -where the fundamental units of analysis are curves representing each individual across time-, in a graphical and automated pipeline for robust analysis of short time-series studies.
Analytes levels are descriptive of the underlying biological state and evolve smoothly through time. For a single analyte, the time trajectory of each individual is described with a smooth curve estimated by smoothing splines. For a group of individuals, a curve representing the group mean trajectory is also calculated. These individual and group mean curves become the new observational unit for subsequent data analysis, that is, the estimation of the intra-class variability and the identification of trajectories significantly altered between groups.
Designed initially for metabolomic, santaR is also suited for other Systems Biology disciplines. Implemented in R and Shiny, santaR is developed as a complete and easy-to-use statistical software package, which enables command line and GUI analysis, with fast and parallel automated analysis and reporting. Comprehensive plotting options as well as automated summaries allow clear identification of significantly altered analytes for non-specialist users.
Installation
Install the CRAN release of santaR with:
install.packages("santaR")The development version can be obtained from GitHub:
# Install devtools
if(!require("devtools")) install.packages("devtools")
devtools::install_github("adwolfer/santaR", ref="master")If the dependency pcaMethods is not successfully installed, it can be installed from Bioconductor:
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("pcaMethods")Usage
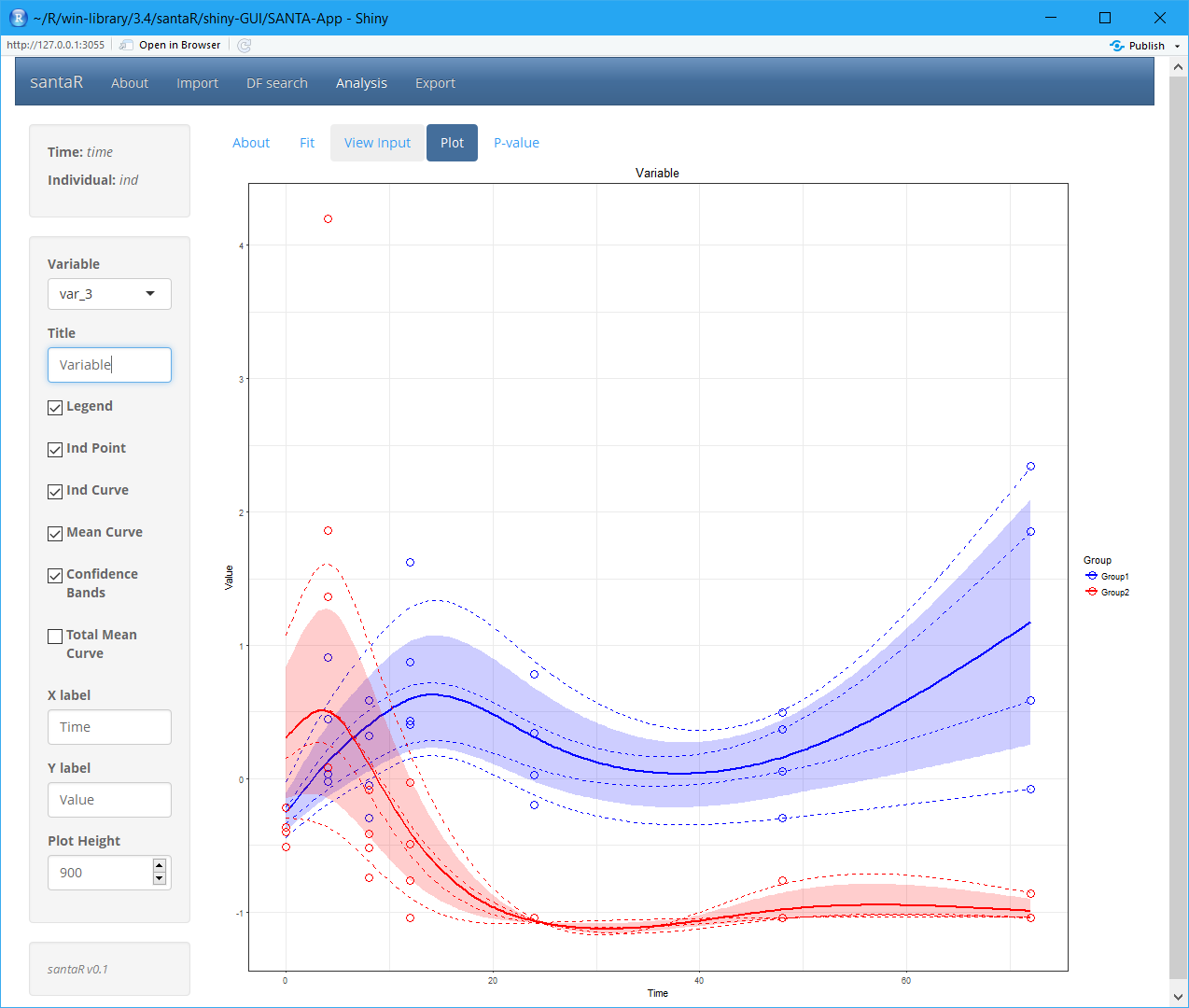
To get started santaR’s graphical user interface implements all the functions for short asynchronous time-series analysis:
library(santaR)
santaR_start_GUI(browser = TRUE)
# To exit press ESC in the command lineThe graphical user interface is divided in 4 sections, corresponding to the main steps of analysis:
Import, DF search, Analysis and Export:
- The Import tab manages input data in comma separated value (csv) format or as an RData file containing a previous analysis. Once data is imported the DF search and Analysis tabs become available.
- DF search implements the tools for the selection of an optimal number of degrees of freedom (df).
- With the data imported and a pertinent df selected, Analysis regroups the interface to visualise and identify variables significantly altered over time. A plotting interface enables the interactive visualisation of the raw data points, individual trajectories, group mean curves and confidence bands for all variables, which subsequently can be saved. Finally, if inter-group differential trajectories have been characterised, all significance testing results (with correction for multiple testing) are presented in interactive tables.
- The Export tab manages the saving of results and automated reporting. Fitted data can be saved as an RData file for future analysis or reproduction of results. csv tables containing significance testing results can also be generated and summary plot for each significantly altered variable saved for rapid evaluation.
Vignettes and Demo data
More information is available in the graphical user interface as well as in the following vignettes:
- Getting Started with santaR
- How to prepare input data for santaR
- santaR Graphical user interface use
- santaR Theoretical Background
- Automated command line analysis
- Plotting options
- Selecting an optimal number of degrees of freedom
- Advanced command line options
A dataset containing the concentrations of 22 mediators of inflammation over an episode of acute inflammation is also available. The mediators have been measured at 7 time-points on 8 subjects, concentration values have been unit-variance scaled for each variable. A subset of the data is presented below:
## Metadata
acuteInflammation$meta| time | ind | group |
|---|---|---|
| 4 | ind_6 | Group2 |
| 4 | ind_7 | Group1 |
| 4 | ind_8 | Group2 |
| 8 | ind_1 | Group1 |
| 8 | ind_2 | Group2 |
| 8 | ind_3 | Group1 |
## Data
acuteInflammation$data| var_1 | var_2 | var_3 | var_4 |
|---|---|---|---|
| 2.668 | 2.464 | 1.365 | 1.743 |
| -0.3002 | 0.05366 | 0.4509 | 0.01572 |
| 3.777 | 2.543 | 1.858 | 2.213 |
| -0.3275 | 0.1564 | 0.585 | 0.03299 |
| 0.708 | 0.4893 | -0.08219 | 0.9345 |
| -0.4101 | -0.03727 | -0.2914 | -0.7239 |
Other tips
The GUI is to be prefered to understand the methodology, select the best parameters on a subset of the data before running the command line, or to visually explore results.
If a very high number of variables is to be processed, santaR’s command line functions are more efficient, as they can be integrated in scripts and the reporting automated.
Copyright
santaR is licensed under the GPLv3
As a summary, the GPLv3 license requires attribution, inclusion of copyright and license information, disclosure of source code and changes. Derivative work must be available under the same terms.
© Arnaud Wolfer (2022)